
Msanii: High Fidelity Music Synthesis on a Shoestring Budget
In this paper, we present Msanii, a novel diffusion-based model for synthesizing long-context, high-fidelity music efficiently. Our model combines the expressiveness of mel spectrograms, the generative capabilities of diffusion models, and the vocoding capabilities of neural vocoders. We demonstrate the effectiveness of Msanii by synthesizing tens of seconds (190 seconds) of stereo music at high sample rates (44.1 kHz) without the use of concatenative synthesis, cascading architectures, or compression techniques. To the best of our knowledge, this is the first work to successfully employ a diffusion-based model for synthesizing such long music samples at high sample rates. Our demo can be found here and our code here.
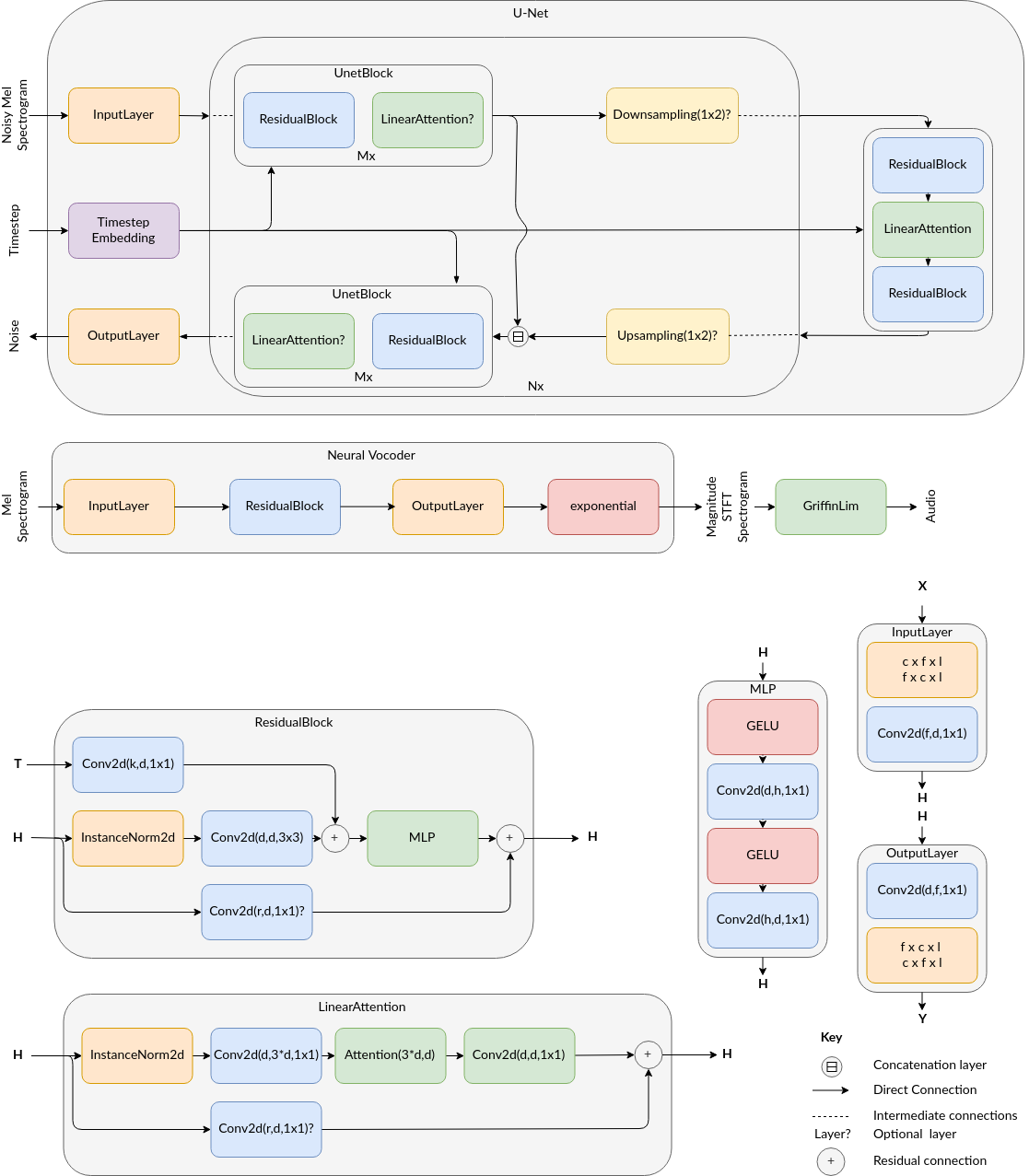
Msanii Architecture
Samples from the Dataset
Samples from the Model
Audio-to-Audio Samples (Style Transfer)
t=0 (original)
t=100
t=500
t=900
Interpolation
Original Audio Samples
Original piano sample
Original drum loop sample
Fixed Noise Timestep and Varying Ratio
t=200,ratio=0.1
t=200,ratio=0.5
t=200,ratio=0.9
Varying Noise Timestep and Fixed Ratio
t=100,ratio=0.5
t=500,ratio=0.5
t=900,ratio=0.5